Data Lakehouse Model: Evolution For Data Insights And AI

With the world becoming data-driven, companies have started collecting data rapidly. This data can help drive business growth, streamline operations, and improve financials if used effectively. However, handling, storing, sorting, manipulating, and utilizing this data can be challenging.
If you want to learn more about handling and managing big data, you are at the right place. In this blog, we’ll explore the evolution of data storage and handling through Data Warehouses, Data Lakes, and Data Lakehouse to see which data analytics option is best for your business.
The blog covers:
What is a Data Warehouse?
A Data Warehouse is a centralized repository that stores structured and semi-structured data collected from various sources. The warehouse is designed for reporting and analysis to make data-driven decisions. The major players in the data warehouse approach are Databricks, Snowflake, Amazon Redshift, Google Big Query, Microsoft Azure Synapse Analytics, and Teradata.
Features of Data Warehouse
Data Warehouse offers various features that allow you to handle and manage your data, making analysis easy to make decisions that can improve your business functionalities. It enables you to process and analyze data with precision and accuracy. The features of a Data Warehouse:
- Data integration – The data is collected from various sources including CRM, databases, and flat files. The data warehouse exacts, transforms, and loads data into the warehouse.
- Historical data storage – The data warehouse also maintains historical data, enabling you to access and analyze it over time.
- Query optimization – It uses techniques like indexing and partitioning for fast query performance.
- BI support – Data warehouse allows your business intelligence tool to perform complex queries to generate insights and make data-driven decisions.
- Schema design – It organizes unstructured data, making navigation and analysis easy. They generally use dimensional modeling to do it.
Benefits of Data Warehouse
Data Warehouse offers advanced features that provide a centralized data source, removing discrepancies while analyzing the data. This unified approach leads to accurate analysis, better decision-making, and enhanced collaboration between various departments. The benefits of a Data Warehouse are:
- Centralized data storage – Data collected from various sources is consolidated in a single place. This provides a single source of truth, making it reliable and providing accurate insights.
- Improved data quality – Data is cleansed during the extraction, transformation, and loading (ETF) process to improve data quality. This increases the data reliability and accuracy.
- Historical analysis – A Data Warehouse stores historical data that can be accessed anytime. You can analyze the trend and make future forecasts using this historical data.
- Enhanced query performance – Unlike transaction databases, Data Warehouse is designed to solve complex queries and provide faster query responses.
- BI support – You can integrate business intelligence tools with the Data Warehouse for advanced analysis, reporting, and visualization.
- Scalability and data security – The Data Warehouse is designed to handle increasing amounts of data without compromising performance. The platform enables you to implement robust security measures, including data access and regular auditing.
- Improved decision-making – The system provides timely and precise data insights, reports, and visualizations that enable you to make fact-based and rational business decisions to support business growth.
- Cost efficiency – Integrating data into unified storage can reduce IT expenses and allow you to use resources efficiently.
Challenges faced in Data Warehousing
Before you put a data warehouse into place, it is essential to comprehend the difficulties you may encounter. Addressing these challenges effectively is the basis of any Data Warehousing project. Common challenges faced in Data Warehousing:
- Implementation complexities – Setting up a Data Warehouse is complicated and involves various challenges. Establishing a successful Data Warehouse requires careful planning, design, and configuration.
- Integration issues – The data is available in various formats that might not be compatible. It is challenging to consolidate data with different formats, structures, and quality.
- Maintenance and management – It is crucial to have ongoing maintenance and support to ensure the system works at its peak and ensure data accuracy, performance, and security.
- Scalability concerns – The data consistently keeps on adding and requires a system that can scale with these increasing amounts of data. This is a major concern as it might add to the costs if your system cannot scale and the amount of data increases.
- Tuning performance – It can be a challenge to keep the data structured and tune queries with continuous data increases. It requires you to consistently monitor and tune data to optimize the performance.
- User adoption – It can be challenging to motivate your team to adopt a new system, especially when they are accustomed to using another system.
- Data compliance – It is challenging to implement and enforce data governance measures with ever-changing policies. You must implement strict data governance policies to ensure data quality and industrial compliance.
- Latency – There can be latency challenges based on the data Warehouse architecture. It can lead to delayed data updates, affecting data analytics and reporting timelines.
- Evolving business needs – The business demands and requirements keep evolving, requiring you to make major adjustments to the system for consistent system performance. This process of adjustments can add complexity and costs.
What is ETL?
ETL (Extract, Transform, Load) refers to extracting, transforming, and loading data from various sources. It is a process used in data warehousing to extract data from various sources and transform it into a suitable format to load the data in the Data Warehouse. The ETL process is repeated every time new data is added. The process ensures that the data is accurate, complete, and updated.
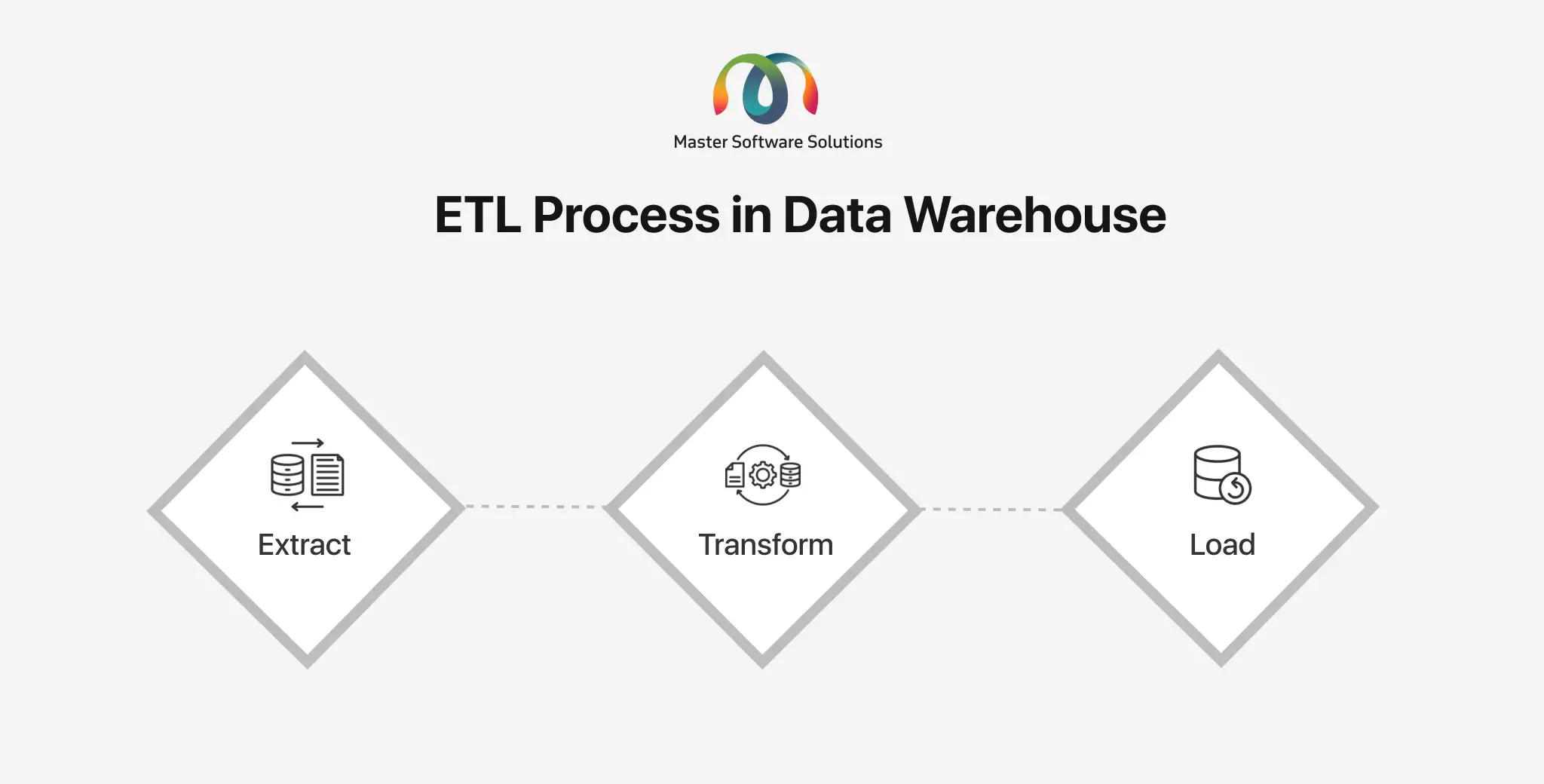
ETL Mechanism
Extract
It is the initial stage in the ETL process where the data is extracted from various sources, including CRMs, transactional sources, or spreadsheets. The process includes reading and storing data in the initial area.
Transform
In this step, the data is converted to a compatible format to load it in the Data Warehouse. Transforming the data includes cleaning, validating, data type conversions, consolidating multiple source data, and creating a new field. The process involved in this step:
- Data cleaning – It removes inconsistencies, duplications, and discrepancies. It also validates the data integrity.
- Data aggregation – The process summarizes the data, applies calculations, and converts the data into a suitable format for loading.
Loading
The data is loaded into the data warehouse in an appropriate format as the final stage of the ETL process.
What is a Data Lake?
A data lake is a unified repository that stores, processes and secures a vast amount of raw data in its original format from its initial stage until it is analyzed. Unlike conventional Data Warehouses that need data to be structured and processed before storing it, data lake stores can handle structured, semi-structured, or unstructured data.
Functionalities of Data Lake
Data Lakes provides a scalable and flexible platform to store a large amount of data, regardless of its format, enabling you to store and process data. The functionalities offered by Data Lakes are:
- Scalability – You can store a large amount of data without hampering performance or incurring additional costs.
- Flexibility – You can store various data types, including text, images, videos, logs, etc. This makes storing diverse data easy.
- Schema-on-read – You can store data without defining schema, which enables you to access it when analyzing data. The ability to apply schema on the readd provides flexibility for data exploration.
- Cost-effective – Data Lake employs cloud-based solutions, which lowers the cost of storing large amounts of data.
- Advanced analytics – Data Lakes enable data scientists to access raw data for experimentation, allowing for advanced techniques like AI and ML, big data processing, and real-time analysis.
- Big data tool integration – You easily integrate Data Lake with big data processing systems like Apache, Hadoop, Spark, and other analytics tools for complex processing.
- Compliance and security – Data Lakes requires compliance with data governance and security policies, ensuring data quality, accuracy, and security.
Benefits of Data Lake
A Data Lake enables you to store and process any data type, regardless of the format. It is greatly beneficial to companies that have diverse data. The benefits of a Data Lake are:
- Cost-effective storage – The Data Lake uses cheaper storage solutions, such as cloud-based solutions, reducing the costs for storing large amounts of data.
- Scalability – Data Lakes are designed to accommodate larger amounts of data, allowing you to add as much data, without affecting system performance.
- Flexibility – Data Lakes are highly flexible when it comes to storing various data types. You can store structures, semi-stuctured, and unstructured data in any format.
- Schema-on-read – The Data lakes allow you to apply schema while analyzing the data. This enables your analysis to be more agile and explanatory, which is beneficial for data scientists and analysts.
- Analytical capabilities – They enable large and advanced big data processors and analytical tools. Such advanced tools support machine learning, complex analysis, and real-time analyses.
- Data Agility – It allows you to ingest and store any new data entering the system from various systems. It doesn’t need exclusive data preparation, which fastens the data-to-insight timeline.
- Data exploration – The system is designed for advanced experimentation and exploration, allowing your team to get insights from raw data.
- Enhanced collaboration – Various departments work together. For instance, data engineers, analysts, and scientists work on common data. Data lakes enable them to work on the same data, fostering enhanced collaboration.
- Data preservation – Data lakes store data in its original format, keeping the original data. This enables you to accommodate evolving analytical needs or compliance.
- Technology integration – You can easily integrate Data Lakes with big data technologies, cloud services, and analytical platforms. This flexibility enables you to stay up-to-date with evolving technology.
Challenges Faced in Data Lakes
Data Lake is an advanced technology that can help companies handle and manage big data without investing much. The Data Lake technology is the newest and has not matured yet, creating an implementation challenge. Challenges faced in data lakes:

- Data swamp risk – Without efficient data handling and management, data lakes can turn into data swamps, resulting in disorganized, outdated, or irrelevant data. This makes it difficult to identify irrelevant data.
- Quality performance – The unorganized and unoptimized data delay the analysis process time and can affect performance quality.
- Governance – It is challenging to manage and ensure data quality, security, and compliance, especially with vast unstructured data.
- Data integration complexities – It is difficult to collect and unify data of various types and formats from various sources.
- Security concerns – Ensuring robust security measures is crucial to protecting the integrity of sensitive data. It is important to protect the data from unauthorized access and breaches.
What is a Data Lakehouse?
The Data Lakehouse is a modern data architecture that combines the functionalities and benefits of Data Lakes (stores raw data in its original form) and Data Warehouse (stores data in structural form). Most of the companies use Data Lakes (for ML workloads) and Data Warehouse (for BI and reporting) to store their structured and unstructured data. But Data Lakehouse totally shifts the entire approach. Data Lakehouses enable you to use cost-effective solutions for data storage, proving structure and management functions.
Functionalities of Data Lakehouses
- Scalable storage and processing – Data Lakehouse is an advanced technology that is highly scalable and scaled with increasing amounts of data and processes using machine learning, business intelligence, and data analysis.
- Various data types – You can store structured, unstructured, and semi-structured data in various formats including images, text, video, etc.
- Supports ACID – Data Lakehouse supports ACID, which stands for Atomicity, Consistency, Isolation, and durability, ensuring consistency when multiple users are reading and writing data.
- Open storage format – Data Lakehouse uses standard formats, such as AVRO, ORC, or Parquet, that are used with software programs.
- Data management – Data Lakehouse offers features, such as schema enforcement, data cleaning, and ETL processing.
- Decoupled storage and computing – In Data Lakehouse, the data storage and computing layers are different, allowing it to scale independently.
Benefits of Data Lakehouse
Data Lakehouse is an advanced and new technology that enables Machine Learning (ML), Business Intelligence (BI), and predictive analysis. This allows businesses to take advantage of cost-efficient storage for all data types while providing data structure and data management features. The benefits of Data Lakehouse are:
- Cost-effective – The low-cost data storage in Data Lakehouses makes it much more cost-effective than data warehouses.
Scalable – The Data Lakehouse is an advanced technology that is highly scalable and can accommodate large amounts of data. - Advanced analytics – It supports data analysis through machine learning, business intelligence, or reporting tools. The flexible integrations allow you to connect advanced analytical tools with Data Lakehouses.
- Simplifies schema – The schema can be applied while analyzing the data. The schema version used in Data Lakehouses is simplified, making data governance and compliance easy.
- Real-time data streaming – The data is updated in real-time and can be used to get real-time insights and make prompt business decisions.
Why is Data Lakehouse the best approach for data storage?
The Data Lakehouse combines the features and functionalities of a Data Warehouse and Data Lake, which offers a robust and efficient data management solution. Reasons that make Data Lakeshouse the best approach for data storage:

- Unifies storage – Data Lakehouses allow you to store all types of data—structured, unstructured, and semi-structured in a single centralized platform.
- Cost efficiency – They use cost-effective data storage solutions that reduce the overhead cost of a Data Lakehouse while handling and managing larger amounts of data.
- Simplified architecture – The unified approach of Data Warehouse and Data Lake removes the need for multiple systems, simplifying the architecture of Data Lakehouse.
- Real-time analytics – Data Lakehouse processes data in real time, enabling you to fetch real-time data insights to make prompt decisions.
- Schema flexibility – It offers schema-on-read features that enable you to define the schema as per requirement for unstructured and semi-structured data. It also supports schema-on-write for structured data.
- Strong performance – It provides optimized data storage format and indexing techniques. It is done to improve query performance, making it easier to analyze large datasets.
- Advanced analytics – The system uses advanced analytical tools like machine learning and artificial intelligence, allowing data scientists and analysts to work with raw data and providing advanced insights.
What are the benefits of a Data Lakehouse over a Data Lake and Data Warehouse?
Data Lakehouse combines all the strengths of Data Lake and Data Warehouse. Here are some key advantages:
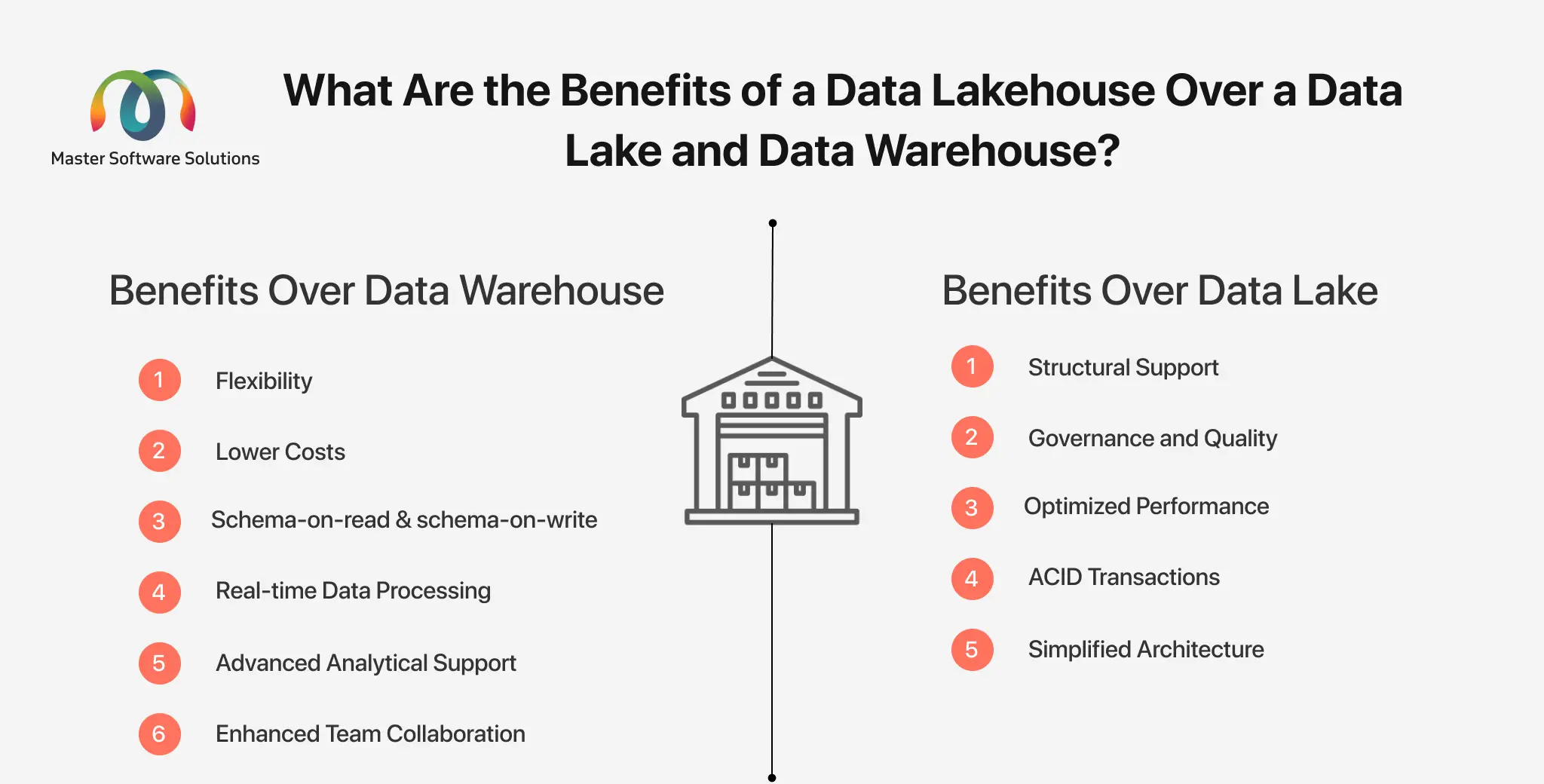
Benefits of Data Lakehouse over Data Lake
- Structural support – Data Lakehouse offers better data support for structured data, queries, and analytics. This enables you to address performance issues that arise only in Data Lakes.
- Governance and quality – Lakehouses include data management and schema features to ensure high data quality and compliance, unlike Data Lakes.
- Optimized performance – Lakehouse uses optimized data storage formats and indexing techniques for improved performance and faster raw data retrieval.
- ACID transactions – Lakehouse supports ACID for reliable data management.
- Simplified architecture – Combining Data Lakes and Data Warehouses removes the need for multiple systems, simplifying its architecture.
Benefits of Data Lakehouse over Data Warehouse
- Flexibility – Data Lakehouses can handle and manage all types of data, including structured, unstructured, and semi-structured in all file formats, such as text, video, images, etc.
- Lower costs – The Lakehouses uses low-cost cloud-based data storage solutions that lower the costs of the entire setup.
- Schema-on-read & schema-on-write – It offers schema-on-read that can be defined at any time as per the requirement, whereas, schema-on-write for structured data.
- Real-time data processing – The system supports real-time data processing and provides live insights, enabling you to make prompt decisions.
- Advanced analytical support – Data lakehouses support the integration of advanced platforms, including machine learning, artificial intelligence, business intelligence, and reporting.
- Enhanced team collaboration – The data stored is accessible to all departments, enabling them to work together on the same data.
Conclusion
There are various Data Lakehouse examples like Databricks, Azure Synapse Analytics, and Snowflakes. These Data Lakehouses are used in various departments of large industries for customer segmentation and targeting, product performance analysis, financial and profitability analysis, supply chain and inventory optimization, sales performance monitoring and forecasting, market campaign effectiveness, operational efficiency analysis, risk management and fraud detection, and retail sales and pricing optimization. If you are looking for experts to help you handle and manage your data, book a call with us and see how we can help.